
Research
Sparrow-0: Advancing Conversational Responsiveness in Video Agents with Transformer-Based Turn-Taking

Written by

Brian Johnson
Written by
Brian Johnson
In this paper, we dive into the development and research behind Sparrow-0, exploring the innovative transformer-based approach for turn-taking and its integration alongside Raven and Phoenix models within our Conversational Video Interface (CVI), an end-to-end operating system designed for building responsive video agents.
Conversational AI systems have long struggled with accurately determining when a speaker has truly finished speaking, creating a critical blind spot in interaction timing. Traditional silence-based methods, relying on fixed periods of silence, often either interrupt users prematurely or introduce noticeable lags, diminishing conversational flow. Sparrow-0, our new foundational turn-detection model, directly addresses this limitation by intelligently identifying conversation endpoints using semantic and lexical analysis. By significantly outperforming conventional silence-detection methods, Sparrow-0 dramatically enhances conversational responsiveness, enabling interactions that feel naturally paced and intuitively human-like.
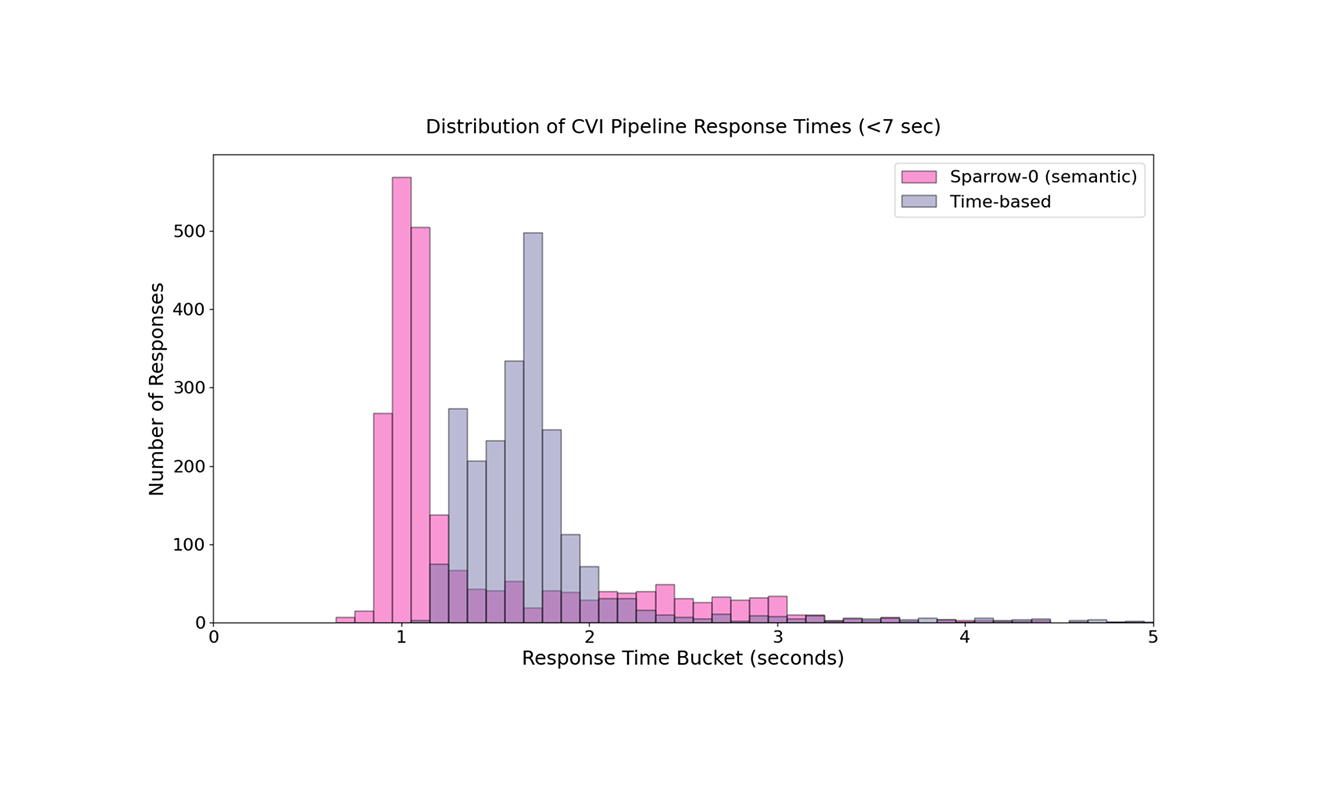
Previously, CVI relied on a fixed wait period of silence. We set this wait period at between 800ms and 1500ms to avoid interrupting speakers mid-sentence. One weakness of the fixed period of silence approach is that if that period is too small, this method frequently results in unintended interjections by the replica. This is due to a tendency for humans to naturally pause in conversation 1-3 seconds while still holding their turn. Another weakness of a purely time-based approach, is that adjusting to a longer 1.3-second threshold lowered interjections but slowed the fastest response times to around 1.7 seconds. Sparrow-0 unlocks the fastest CVI speeds while maintaining smooth turn transitions.

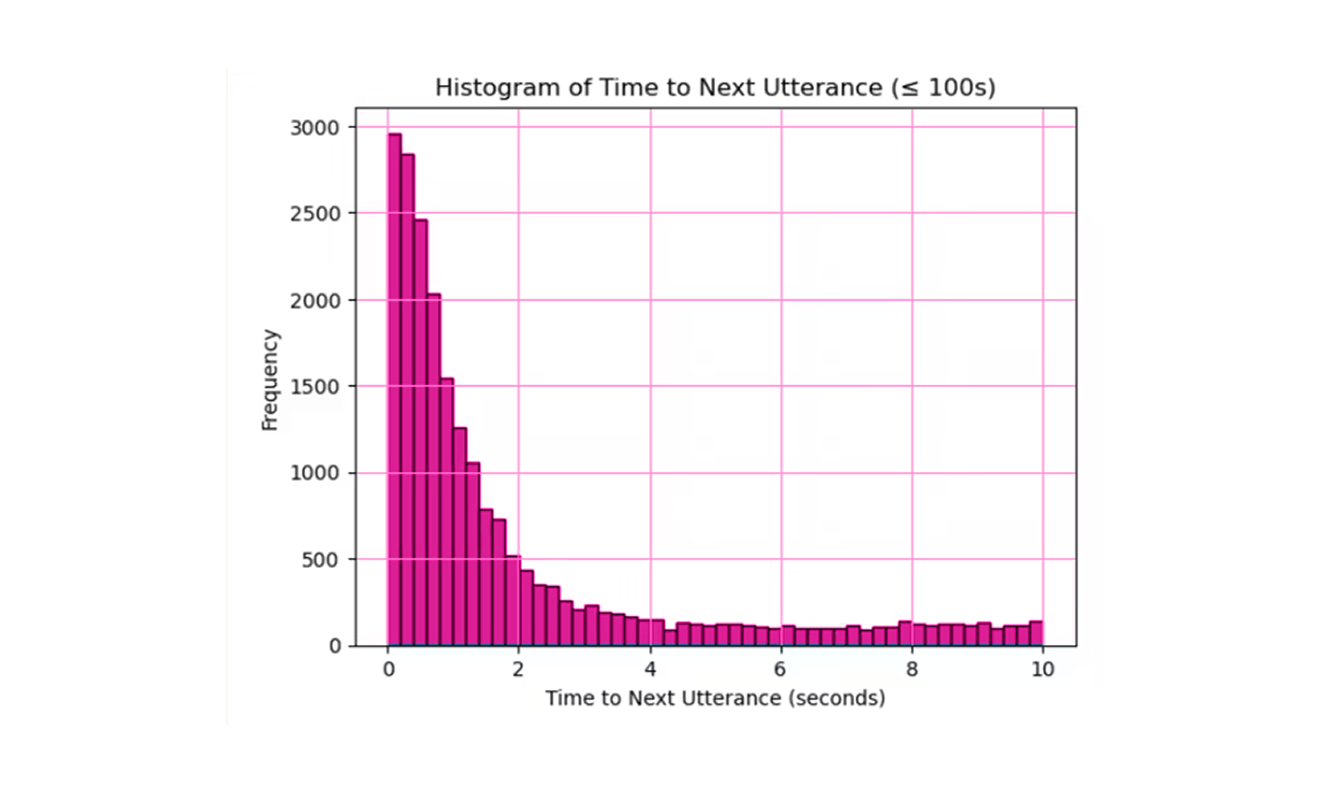
With Sparrow enabled, CVI achieves exceptionally rapid response times. Current benchmarks show CVI is capable of fully generating a response in 600ms, with the modal response time at approximately 1.0 second. We know that responses must often be delayed to avoid interrupting the speaker. The challenge is knowing when to be fast and when to be slow. Sparrow's semantic/lexically driven predictions enable CVI to respond at its highest speed, because Sparrow knows when a speaker is done precisely when they finish, and Sparrow also knows when to wait for a speaker to finish, giving Sparrow-enabled conversations a substantially snappier feeling than traditional methods, while also maintaining a smooth conversation by not interrupting the speaker.
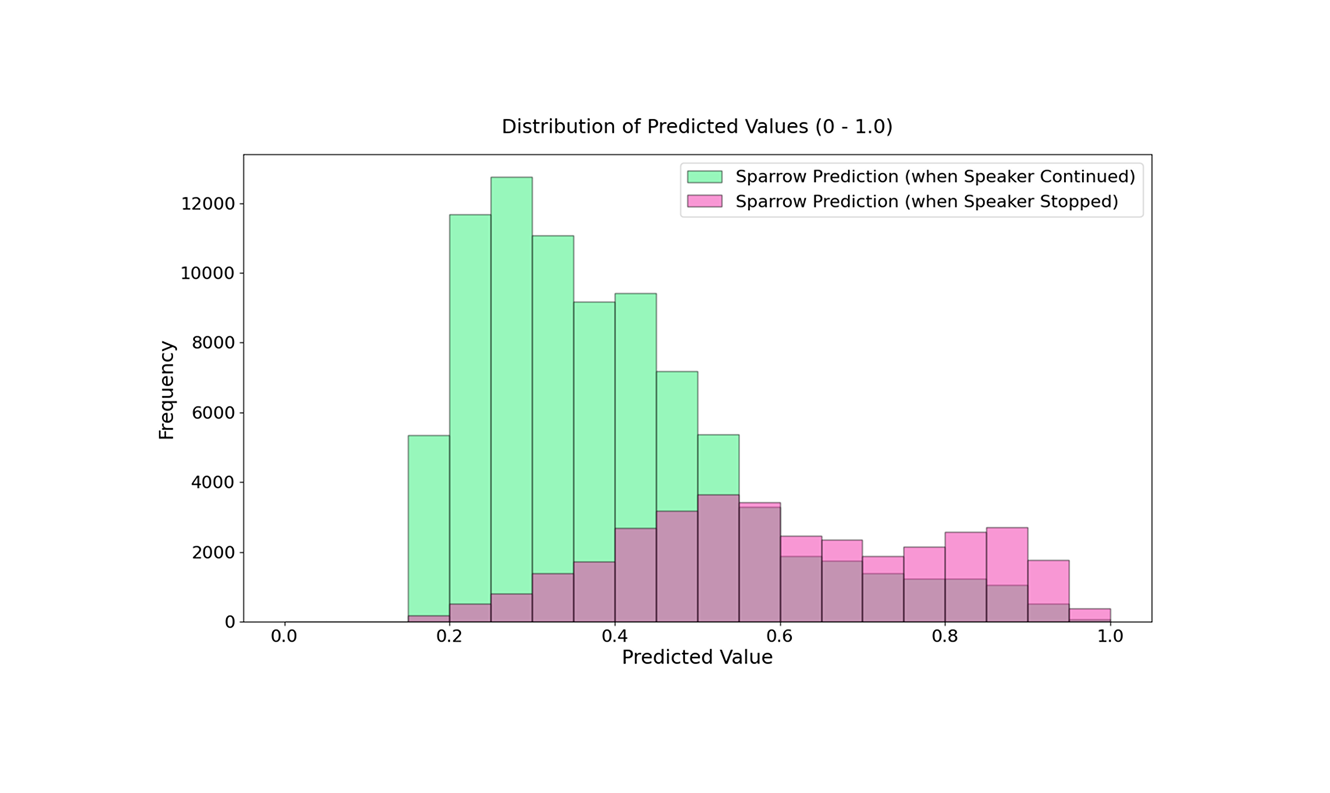
Sparrow analyzes utterances each time a speaker briefly pauses (for 100ms), predicting whether the speaker is finished based solely on the content spoken up to that point. After predictions are made, pauses are recorded and analyzed. Typically, Sparrow produces low confidence (below 0.52) scores for utterances preceding short pauses such as breaths. We expect there to be many more of these short pauses, as people can pause many times in a single sentence. Whereas utterances preceding meaningful/longer pauses indicating sentence completion yield higher scores (above 0.5). This sophisticated differentiation highlights Sparrow’s ability to accurately infer conversational intent and timing.
An ideal turn-detection system precisely matches human conversational dynamics. Sparrow closely approximates this ideal, maintaining response times near CVI’s modal optimal conversational benchmark of roughly 1 second. This ensures interactions remain smooth and natural, closely mirroring human-like conversational timing.
Research across diverse languages and cultures consistently finds human conversational response times clustering around 250ms. Even the slowest natural responses rarely exceed 1.6 seconds. Sparrow’s design aligns closely with these human conversational benchmarks, enabling conversational AI that feels remarkably natural.
At the core of Sparrow-0 has a BERT-base architecture, with strong multilingual capabilities and deep semantic richness. Sparrow-0 is trained specifically for conversational turn prediction. It demonstrates strong multilingual performance, supporting over 100 languages with minimal impact on accuracy.
Model evaluation metrics underline its robust performance:
To build Sparrow-0, we overcame significant data and modeling challenges:
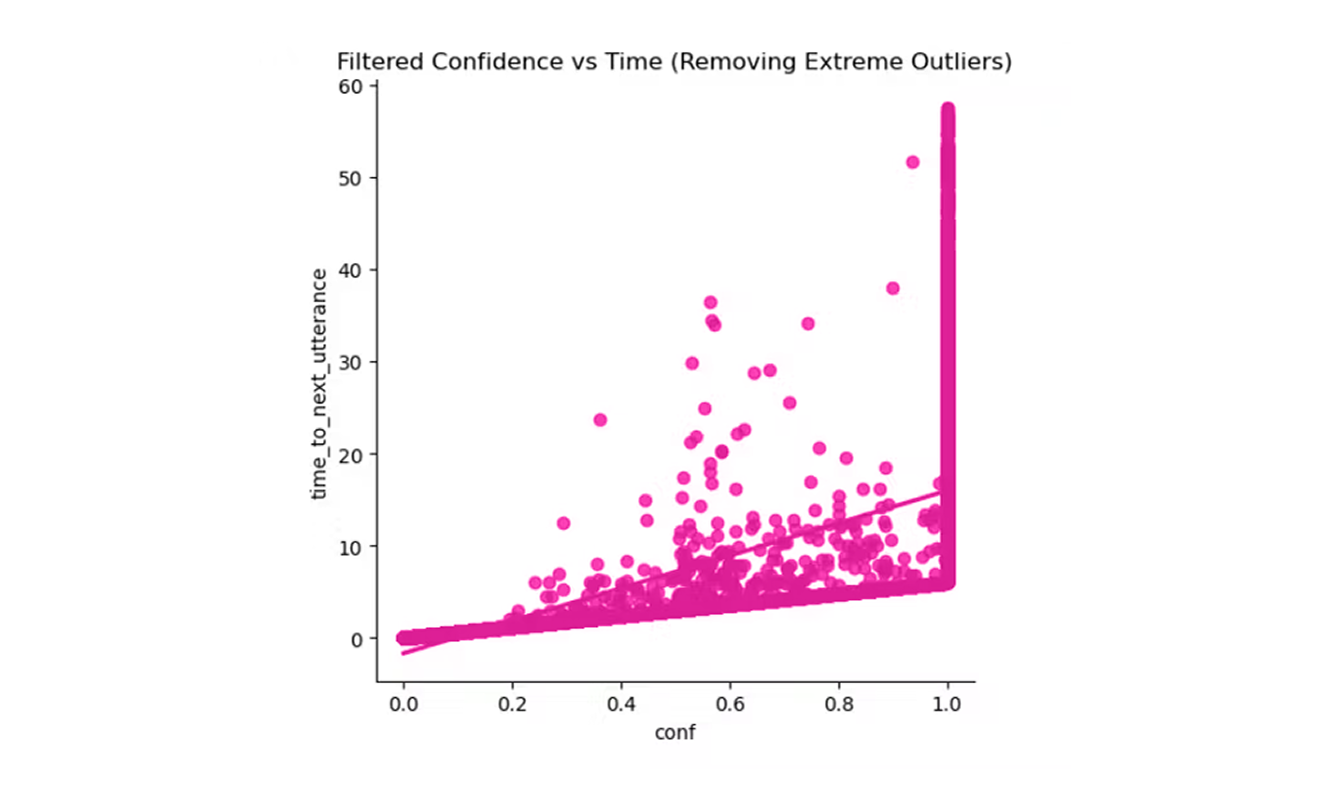
Sparrow-0 leverages transformer-based regression to predict pause durations precisely. This approach capitalizes on deep semantic context, enhancing the model's effectiveness across multiple languages and varied conversational nuances.
We apply an inverse sigmoid transformation to Sparrow’s regression outputs, converting normalized predictions into actionable confidence scores. High-confidence scores prompt immediate AI responses, while lower scores encourage appropriate delays, effectively balancing responsiveness and conversational etiquette.
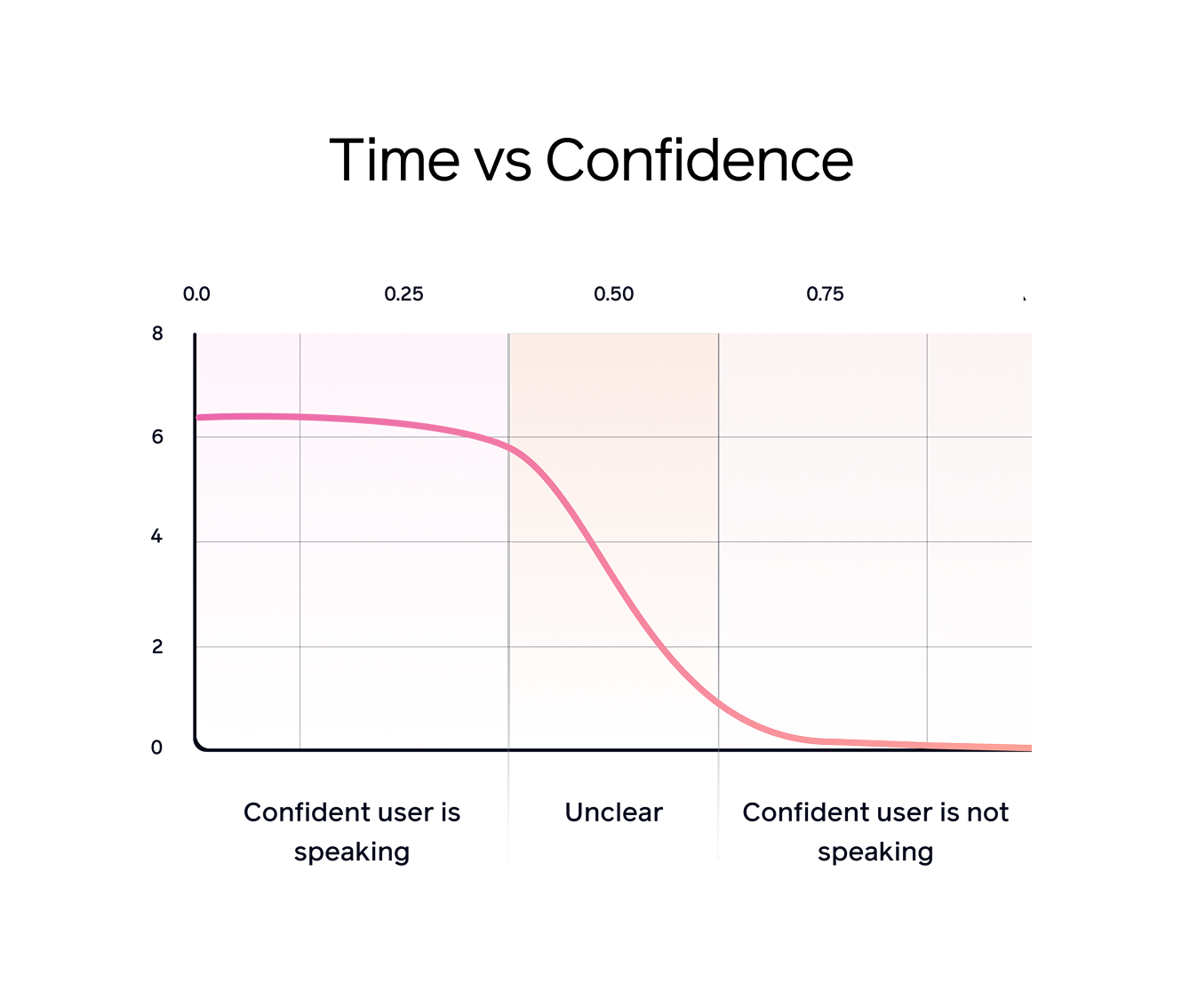
Sparrow-0 marks a significant leap forward in conversational AI, fundamentally transforming how naturally and effectively AI agents engage with users. Now activated by default in Tavus CVI, Sparrow-0 delivers immediate improvements, including a remarkable 50% boost in user engagement, an 80% higher retention rate compared to traditional pause-based methods, and nearly two times faster responses at around 610ms per interaction—providing fluid, interruption-free conversations that seamlessly balance speed and thoughtful pauses.
Developers also now have the ability to customize the model's sensitivity, enabling tailored conversational behaviors for unique and specialized use cases. Sparrow-0’s advanced turn-taking capability fosters deeper, richer conversations, establishing a new benchmark for conversational AI. As we further develop this research, future iterations of the Sparrow model line will continue driving the frontier of human-like AI conversations.
