
All Posts
Research
Hummingbird-0: Advancing Zero-Shot Lip Synchronization in AI-Generated Video

Written by

Yevhenii Petrenko
All Posts
Written by
Yevhenii Petrenko
Hummingbird-0 began as an surpise offshoot of our research into full-face conversational AI. During development of Phoenix-3, we isolated a pathway for optimizing lip synchronization independently—without compromising identity or visual quality. The result is Hummingbird: a zero-shot lip sync model that delivers state-of-the-art performance across lip sync accuracy, identity preservation, and visual fidelity.
This paper outlines the architecture, benchmarks, and technical contributions of the model, as well as its implications for scalable, cost-effective content personalization.
We made an unexpected discovery while developing our premium conversational AI technology. Components of our advanced video pipeline could be isolated and explicitly optimized for lip synchronization, with remarkable results. This serendipitous research byproduct evolved into Hummingbird, a specialized zero-shot lip-sync model that achieves state-of-the-art performance compared to other leading solutions.
What began as a technical curiosity quickly revealed its potential as we benchmarked Hummingbird against leading industry zero-shot lip sync systems. The model demonstrated exceptional capabilities in visual quality, lip synchronization accuracy, and identity preservation.
While our comprehensive solutions remain our flagship offering for facial animation and emotional expression, Hummingbird addresses several critical challenges in more focused video content creation:
Our comprehensive evaluation against industry-leading zero-shot lip sync solutions across 30+ diverse videos revealed:
Hummingbird represents a significant advancement in the democratization of high-quality video personalization technology, providing an accessible solution for creating lip-synchronized content without requiring specialized training.
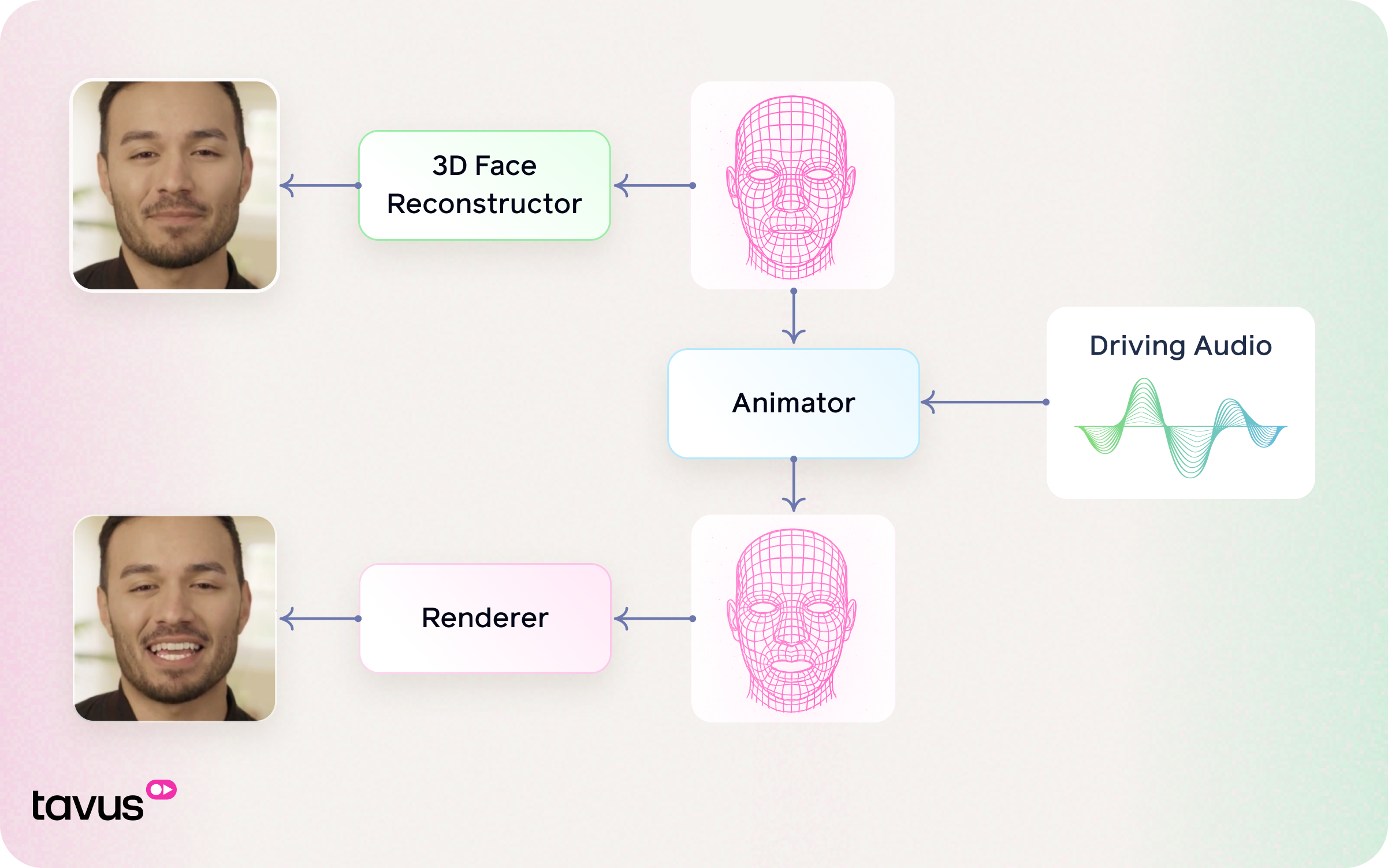
The Hummingbird model is designed to modify the lip movements in a given video so that they match the content of a driving audio signal. The core idea is to preserve the original identity, expressions, and visual quality of the person in the video, while synchronizing their lip movements with the new audio. The entire process can be broken down into three main stages:
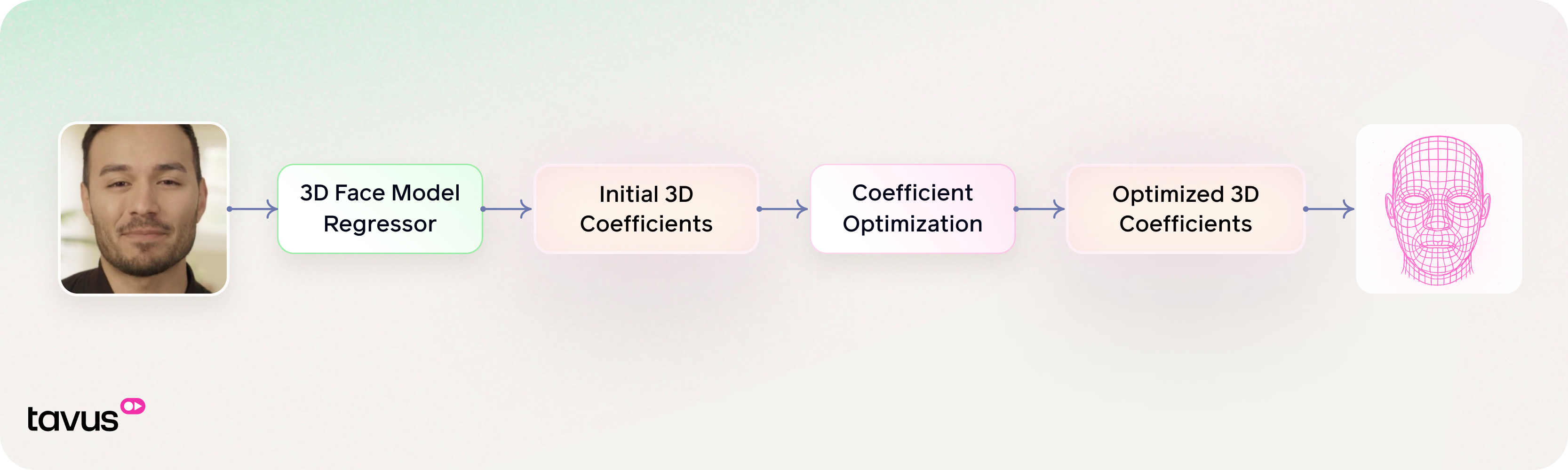
The 3D Face Reconstruction pipeline starts by processing an input image frame through a pre-trained 3D Face Model Regressor, which estimates a set of coefficients encapsulating key facial attributes, including shape, expression, pose, and camera parameters to reconstruct a detailed and realistic 3D face mesh, faithfully capturing both the identity and expression of the subject. This high-precision reconstruction supports a range of downstream applications such as facial animation, avatar creation, and performance-driven facial tracking.
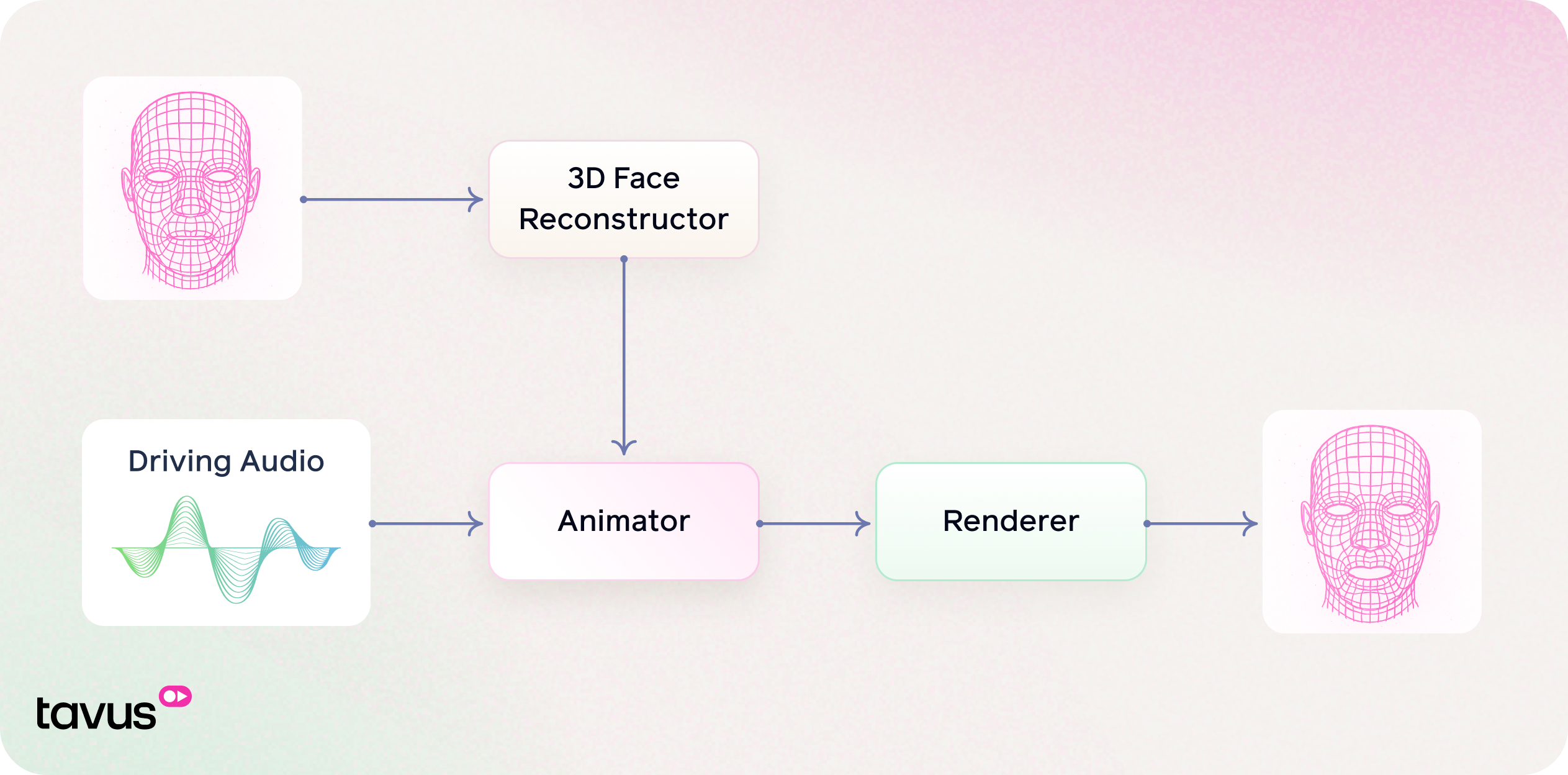
Leveraging a state‐of‐the‐art approach, our animator transforms input audio and 3D facial data into a dynamic sequence of expression coefficients that drive precise lip movements. In addition to mapping acoustic features and fundamental facial structure, the system incorporates a dedicated style input which captures speaker-specific nuances to generate personalized and stylized motions. The deep learning model integrates these diverse cues to determine the optimal parameters for smoothly deforming a 3D mesh over time. Trained on a large-scale dataset of paired audio and facial motion data, this approach demonstrates robust zero-shot performance, effectively animating new and unseen speakers while preserving high visual realism alongside individualized stylistic expression.
.png)
The Renderer generates the final output frame by combining three key inputs: the original frame, 3D facial motion, and visual references.
Starting from the Original Frame, facial motion is guided by Driving 3D Geometry, which encodes the target expressions and mouth movements. At the same time, Reference Frames provide texture and appearance cues to maintain the subject’s identity and visual consistency.
By integrating these inputs, the renderer produces an Output Frame that reflects the desired expression while preserving the person’s original appearance. This approach ensures natural lip synchronization and realistic facial animation, even across varying poses and expressions.
Once trained, the system can synthesize expressive and coherent talking head videos without any fine-tuning for specific individuals.
Hummingbird demonstrates that high-quality, zero-shot lip synchronization is not only possible, it’s practical and deployable today. By isolating the lip sync component, we’ve created a model that enables creators and developers to work with existing footage while introducing new audio, eliminating the need for reshoots or complex post-production.
You can explore Hummingbird in the FAL model gallery, access it through the Tavus API, and as always, review integration guidance in our developer documentation. We’ve launching Hummingbird in research preview and welcome feedback from the community as we continue refining the model.
