
Research
Phoenix-2: Advanced Techniques in Talking Head Generation — 3D Gaussian Splatting

Written by

Christian Safka
Written by
Christian Safka
This paper will cover the past, present and future of the talking-head generation research field. Specifically, we will dive deep into the trending 3D scene representations (NeRF -> 3DGS) and the benefits of employing 3DGS in avatar applications.
Talking Head model architectures have varied significantly over recent years, from fully two-dimensional approaches utilizing Generative Adversarial Networks (GANs) [0], to 3D rendering pipelines such as audio-driven Neural Radiance Fields (NeRFs) [1] or 3D Gaussian Splatting (3DGS) [2].
Traditional GAN models leveraged large datasets of facial images to produce realistic facial animations, but often struggled with temporal consistency and coherence across longer sequences.
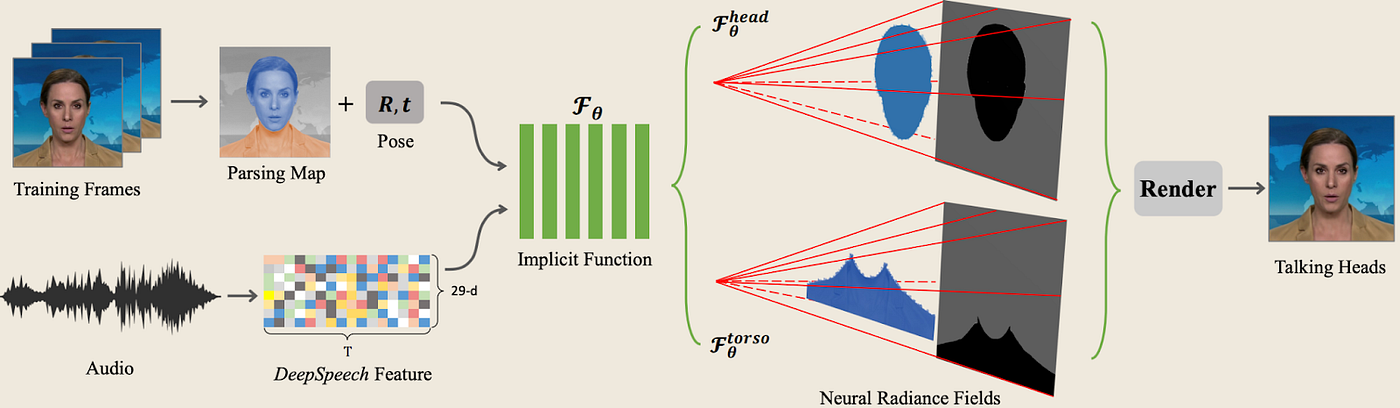
The transition from image GANs to NeRFs has brought notable improvements in training time requirements, render speed, and video quality. GANs by nature require vast datasets and expensive computational resources for training, and often result in slower inference times and lower video quality due to the two-dimensional nature and temporal consistency issues. By using 3D intermediates, we are able to take advantage of fast rendering techniques over 100 FPS, as well as utilize a higher degree of controllability and generalizability due to physics-aware constraints around expression animation. A visual comparison illustrates the difference between 2D and 3D talking-head models.

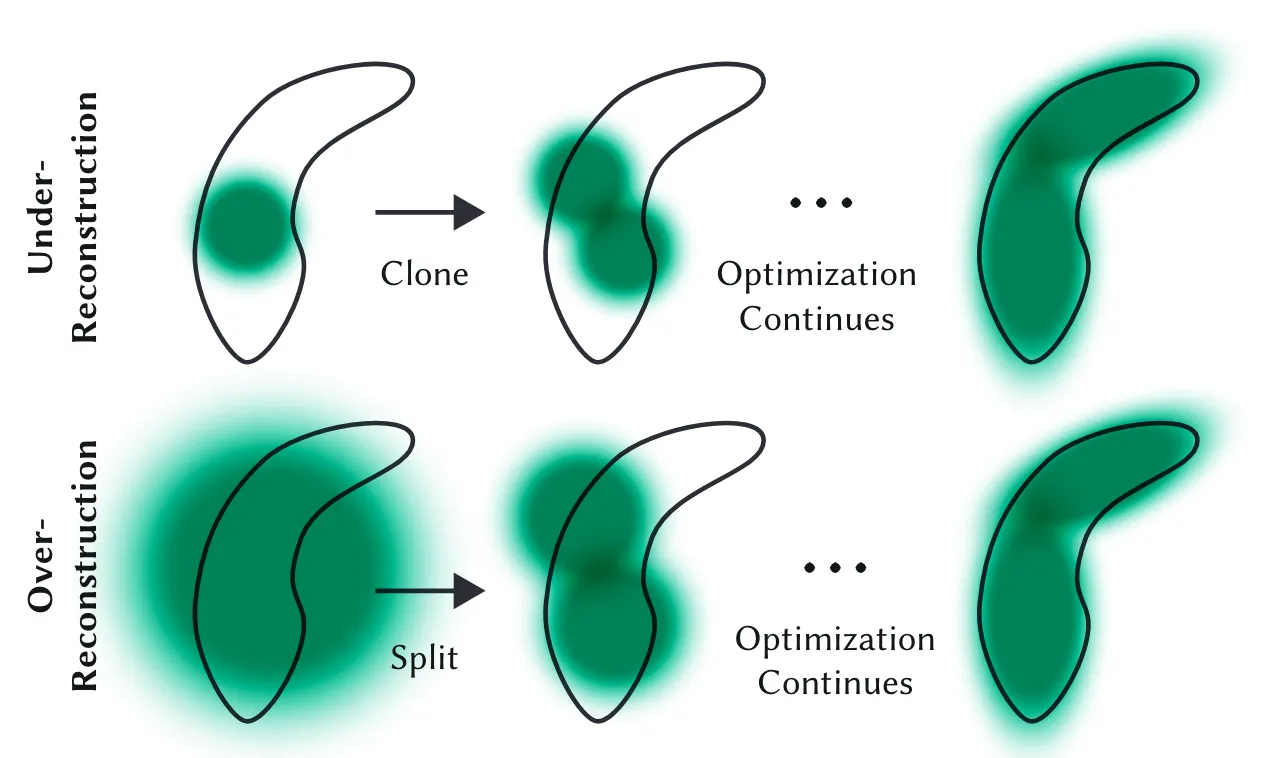
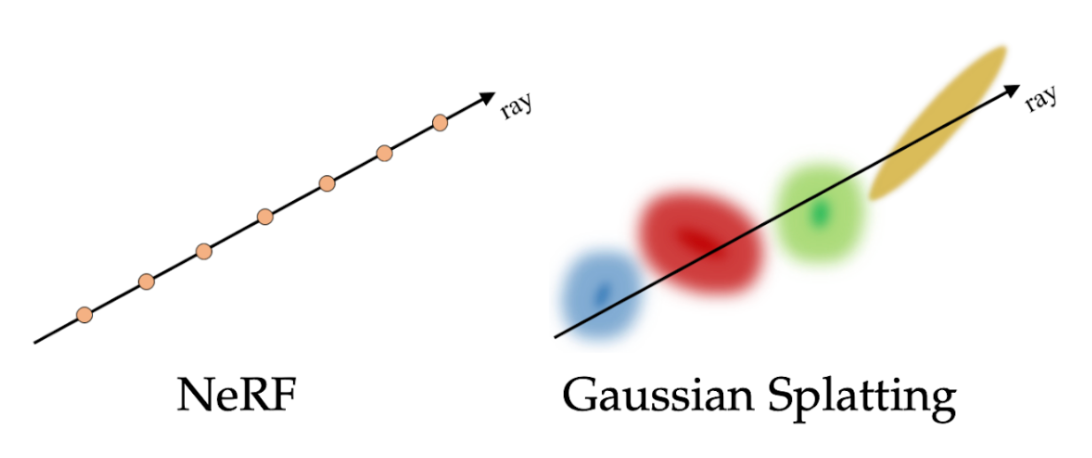
3D Gaussian Splatting is a cutting-edge rasterization technique used in the field of 3D scene representation. Unlike previous methods, 3DGS employs a novel mechanism that leverages Gaussian splats — essentially small, localized, Gaussian-distributed elements — to represent 3D scenes.
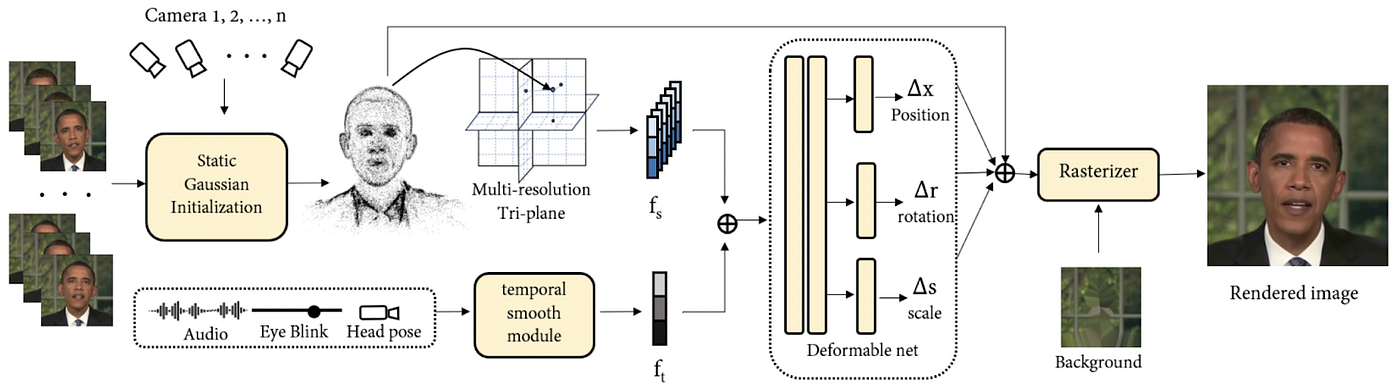
One of the most impactful improvements we made from the Phoenix model to the Phoenix-2 model was doing a drop-in replacement of the NeRF backbone of the original Phoenix model. The Phoenix-2 model now uses 3DGS to learn how audio deforms faces in 3D space, and uses that information to render novel views from unseen audio. Building on that foundation, Phoenix-3 delivers full-face animation with precise micro-expressions and emotion support in real time, achieving studio-grade fidelity and strong identity preservation.
The advantages of Gaussian Splatting over ray-tracing NeRFs are seen across several categories:
1. Data Representation
2. Memory Usage
3. Computational Complexity
4. Training Process
5. Rendering Efficiency

Our Phoenix-3 pipeline based on 3DGS is able to train new AI humans 70% faster, render at 60+ FPS, and allow for a more explicit controllability due to the nature of working with the primitive Gaussian Splat scene representations.
This transition enhances the practicality of deploying these models in real time for face-to-face interactions, and enables more explicit control over on-screen behavior.
In the past few months, several concurrent research papers have been published/open released in this area. For example, GSTalker (Chen et al)[6], GaussianTalker (Cho et al) [7], GaussianTalker (Yu et al)[9], TalkingGaussian (Li et al)[8], to name just a few, all indicate that employing 3D gaussian splatting techniques into the talking head generation task is a promising direction.
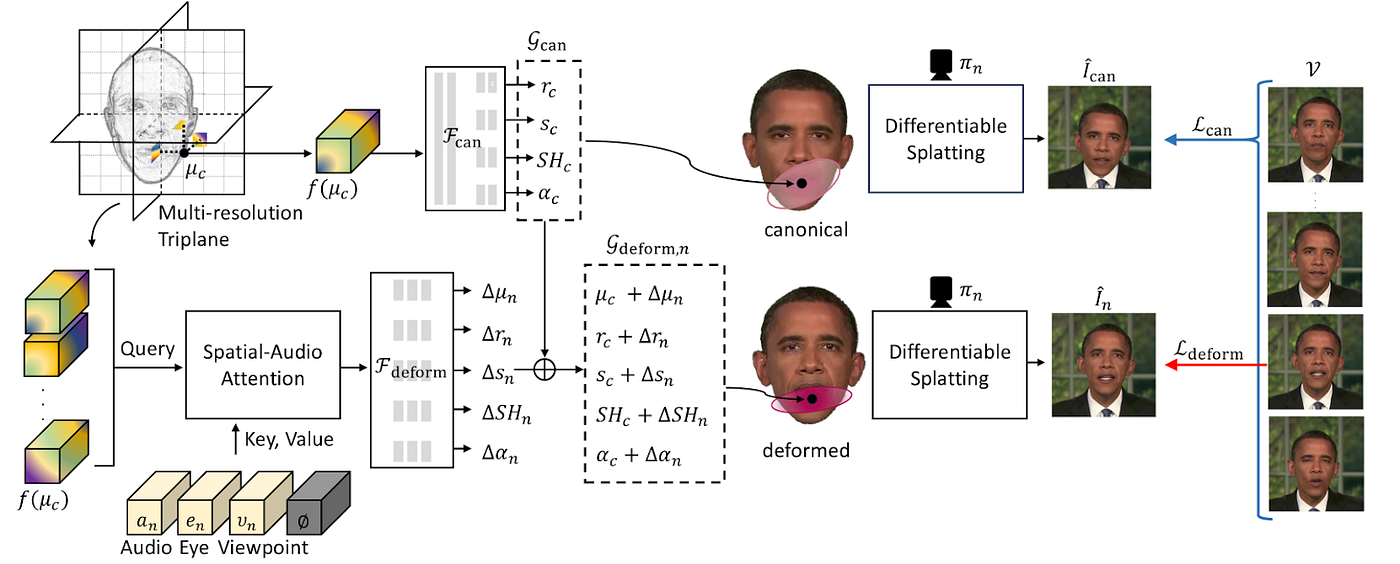
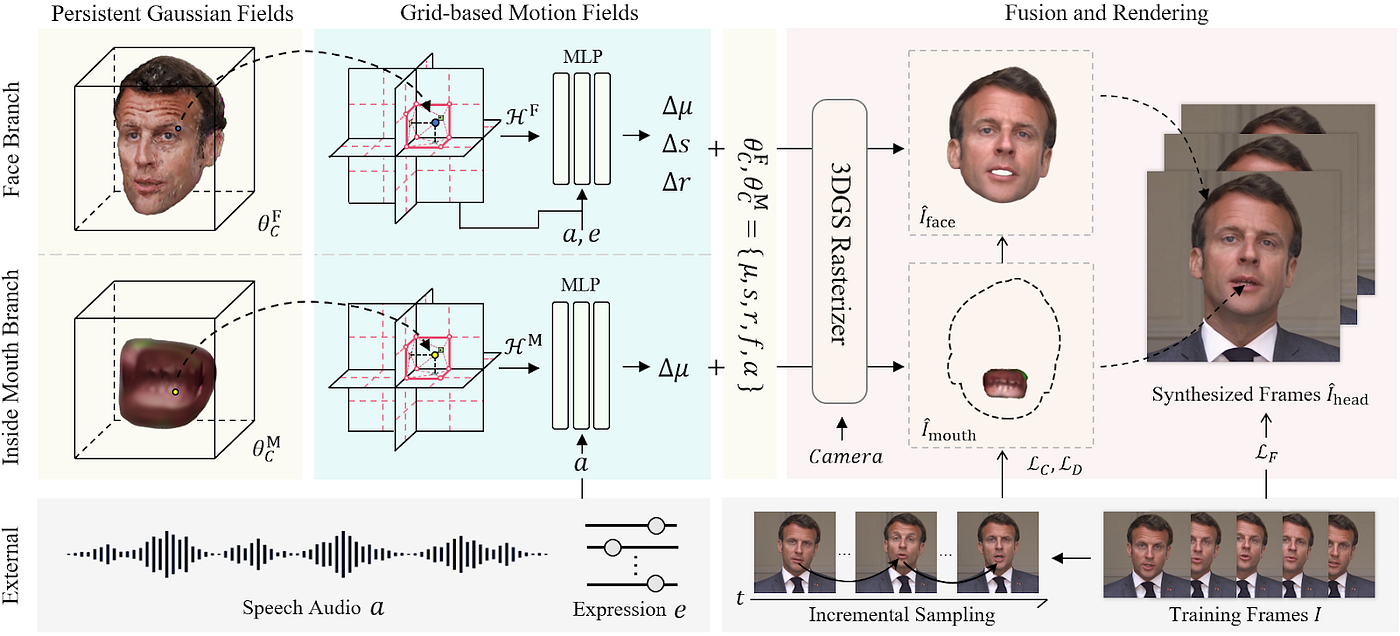

While a positively-trending direction, there are still some known limitations in 3DGS-based methods. First, these methods would suffer from render quality issues, especially for in-the-wild training videos. Second, the training time requirement from the above methods is still too high for real world applications.
With Phoenix-3, we were able to build off of existing methods and combine them with our in-house novel advancements to tackle these limitations. If this is something that sounds interesting to you, come check us out! We’re hiring: https://tavus.io/careers
References
[0] Goodfellow, Ian, et al. “Generative adversarial nets.” Advances in neural information processing systems 27 (2014).
[1] Guo, Yudong, et al. “Ad-nerf: Audio driven neural radiance fields for talking head synthesis.” Proceedings of the IEEE/CVF international conference on computer vision. 2021.
[2] Kerbl, Bernhard, et al. “3D Gaussian Splatting for Real-Time Radiance Field Rendering.” ACM Trans. Graph. 42.4 (2023): 139–1.
[3] Gupta, Anchit, et al. “Towards generating ultra-high resolution talking-face videos with lip synchronization.” Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2023
[4] Tosi, Fabio, et al. “How nerfs and 3d gaussian splatting are reshaping slam: a survey.” arXiv preprint arXiv:2402.13255 4 (2024).
[5] Tosi, Fabio, et al. “How nerfs and 3d gaussian splatting are reshaping slam: a survey.” arXiv preprint arXiv:2402.13255 4 (2024).
[6] Chen, Bo, et al. “GSTalker: Real-time Audio-Driven Talking Face Generation via Deformable Gaussian Splatting.” arXiv preprint arXiv:2404.19040 (2024).
[7] Cho, Kyusun, et al. “GaussianTalker: Real-Time High-Fidelity Talking Head Synthesis with Audio-Driven 3D Gaussian Splatting.” arXiv preprint arXiv:2404.16012 (2024).
[8] Li, Jiahe, et al. “TalkingGaussian: Structure-Persistent 3D Talking Head Synthesis via Gaussian Splatting.” arXiv preprint arXiv:2404.15264 (2024).
[9] Yu, Hongyun, et al. “GaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting.” arXiv preprint arXiv:2404.14037 (2024).
